 minto.tech スマホ(Android/iPhone)・PC(Mac/Windows)の便利情報をお届け! 月間アクセス160万PV!スマートフォン、タブレット、パソコン、地デジに関する素朴な疑問や、困ったこと、ノウハウ、コツなどが満載のお助け記事サイトはこちら!
minto.tech スマホ(Android/iPhone)・PC(Mac/Windows)の便利情報をお届け! 月間アクセス160万PV!スマートフォン、タブレット、パソコン、地デジに関する素朴な疑問や、困ったこと、ノウハウ、コツなどが満載のお助け記事サイトはこちら!
※本ページにはプロモーション(広告)が含まれています
【2026年最新版】Stable Diffusionのインストール・使い方完全ガイド|ローカル環境で無料AI画像生成
「AIで画像を生成してみたいけど、毎月の料金が気になる」「自分のPCで好きなだけ画像を作りたい」——そんな方に最適なのが、完全無料でローカル環境(自分のPC)で動かせるAI画像生成ツール「Stable Diffusion」です。
Stable Diffusionは、PCに一度セットアップすれば月額料金なしで無制限に画像を生成できます。高性能なGPUさえあれば、MidjourneyやDALL-E 3に匹敵する高品質な画像をいつでも生成可能です。
この記事では、最も人気の高いWebUI「AUTOMATIC1111(Stable Diffusion web UI)」のインストール方法から基本的な使い方まで、初心者にもわかりやすく解説します。2026年最新の環境に対応した完全ガイドです。
この記事でわかること
- Stable DiffusionとMidjourneyの違い
- 動かすために必要なPCスペック・GPU要件
- AUTOMATIC1111 WebUIのインストール手順(WindowsおよびMac)
- 基本的な画像生成方法(txt2img)
- プロンプトとネガティブプロンプトの書き方
- 追加モデル(チェックポイント)の導入方法
- よくあるトラブルと解決方法
Stable Diffusionとは
Stable Diffusion(ステーブル ディフュージョン)は、ドイツのLMU Munichとイギリスのスタートアップ企業Stability AIが共同開発した、オープンソースのAI画像生成モデルです。2022年8月に公開されて以来、その高い画像品質と完全無料・ローカル動作という特性から世界中の開発者・クリエイターに広まりました。

Stable Diffusionの主な特徴
- 完全無料・オープンソース:モデルの重みファイルも含めてオープンソースで公開されており、誰でも無料で使える
- ローカル動作:インターネット接続不要で自分のPC上で動作。生成データがクラウドに送られない
- 無制限生成:一度セットアップすれば何枚でも制限なく生成できる
- 高い拡張性:多数のコミュニティ製モデル(チェックポイント)・LoRA・プラグイン(Extension)で機能を大幅に拡張できる
- 商用利用可能:モデルのライセンス(Stable Diffusion License)に従えば商用利用が可能
Stable DiffusionとMidjourneyの違い比較
| 項目 | Stable Diffusion | Midjourney |
|---|---|---|
| 料金 | 無料(ローカル動作) | 有料プラン中心(最新料金は公式サイトで確認) |
| 初期設定の難しさ | 難(環境構築が必要) | 易(登録すればすぐ使える) |
| 画像品質 | 高い(モデル次第) | 非常に高い |
| カスタマイズ性 | 非常に高い | 中程度 |
| プライバシー | 完全ローカル(データ不要) | クラウドに送信される |
| インターネット接続 | 不要(初回DLのみ) | 必須 |
| 生成速度 | GPU次第(高性能GPUで数秒) | 15〜60秒(サーバー処理) |
| モデルの多様性 | 非常に多い(何千種類も) | 限定的 |
必要な動作環境・GPU要件
Stable Diffusionをローカルで動かすには、ある程度のPCスペックが必要です。特にGPU(グラフィックカード)のVRAM(ビデオメモリ)が最重要要件になります。
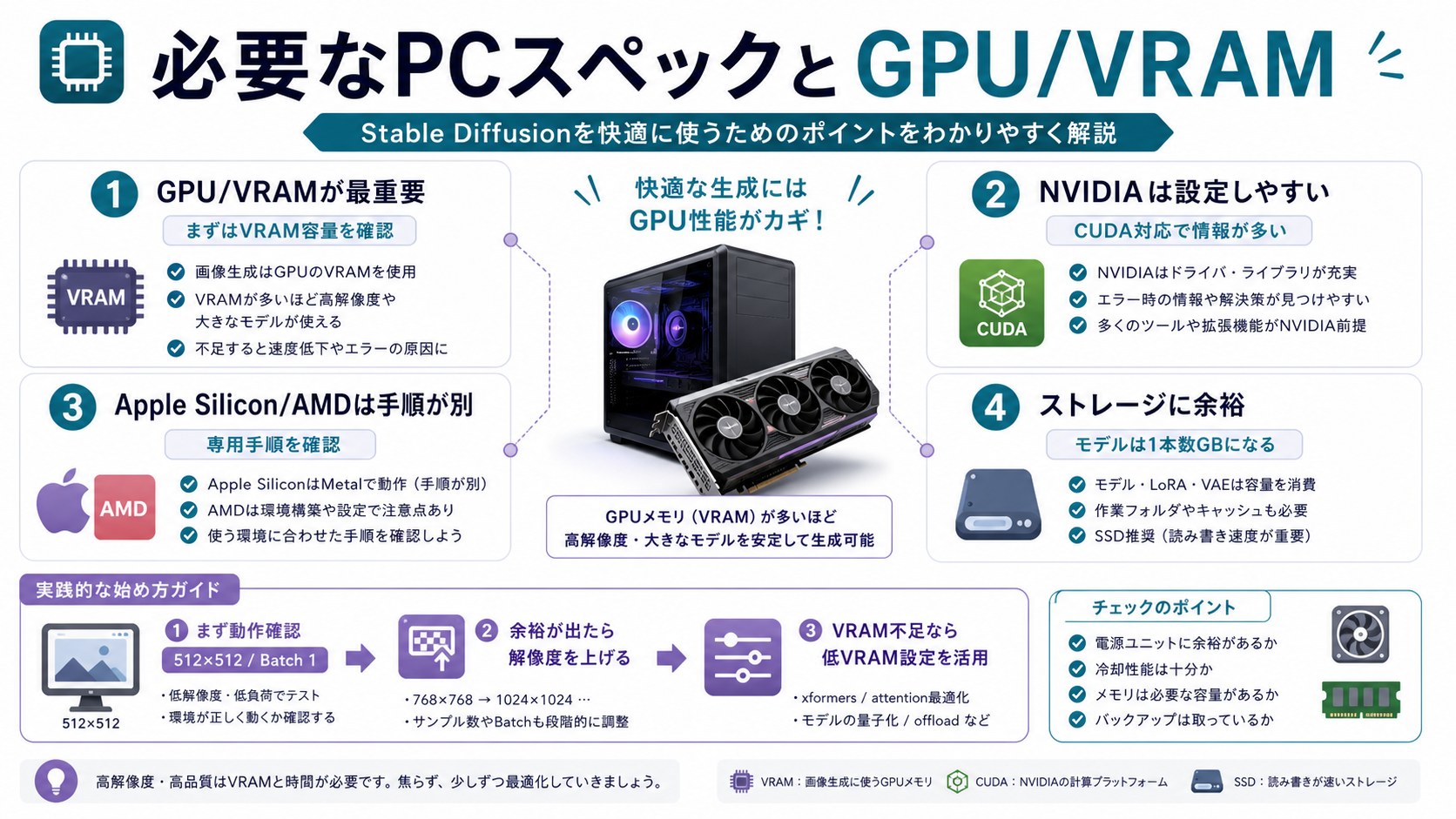
推奨・最低動作環境
| コンポーネント | 最低要件 | 推奨スペック |
|---|---|---|
| OS | Windows 10 / macOS 12.3以降 | Windows 11 / macOS 13以降 |
| GPU(VRAM) | NVIDIA 4GB VRAM(例:GTX 1650) | NVIDIA 8GB以上(例:RTX 4060以上) |
| RAM | 8GB | 16GB以上 |
| ストレージ | 20GB以上の空き容量 | SSD 50GB以上(モデルは1本4〜7GB) |
| インターネット | 初回セットアップ時のみ必要 | 初回セットアップ時のみ必要 |
GPUに関する注意事項
- NVIDIA GPU(推奨):CUDA対応のためパフォーマンスが最も高い。GTX 1060(6GB)以上を推奨
- AMD GPU:ROCm(Linux)またはDirectML(Windows)での動作が可能だが、NVIDIAより設定が複雑
- Apple Silicon(M1/M2/M3/M4チップ):Metal Performance Shaders経由で動作可能。VRAM非搭載だが統合メモリで代替できる
- CPU(GPUなし):動作は可能だが非常に低速(1枚の生成に数分〜十数分かかる)
AUTOMATIC1111 WebUIのインストール手順
AUTOMATIC1111 Stable Diffusion web UI(以下AUTOMATIC1111)は、最も普及しているStable Diffusionのインターフェイスです。ブラウザ上で直感的に操作できます。
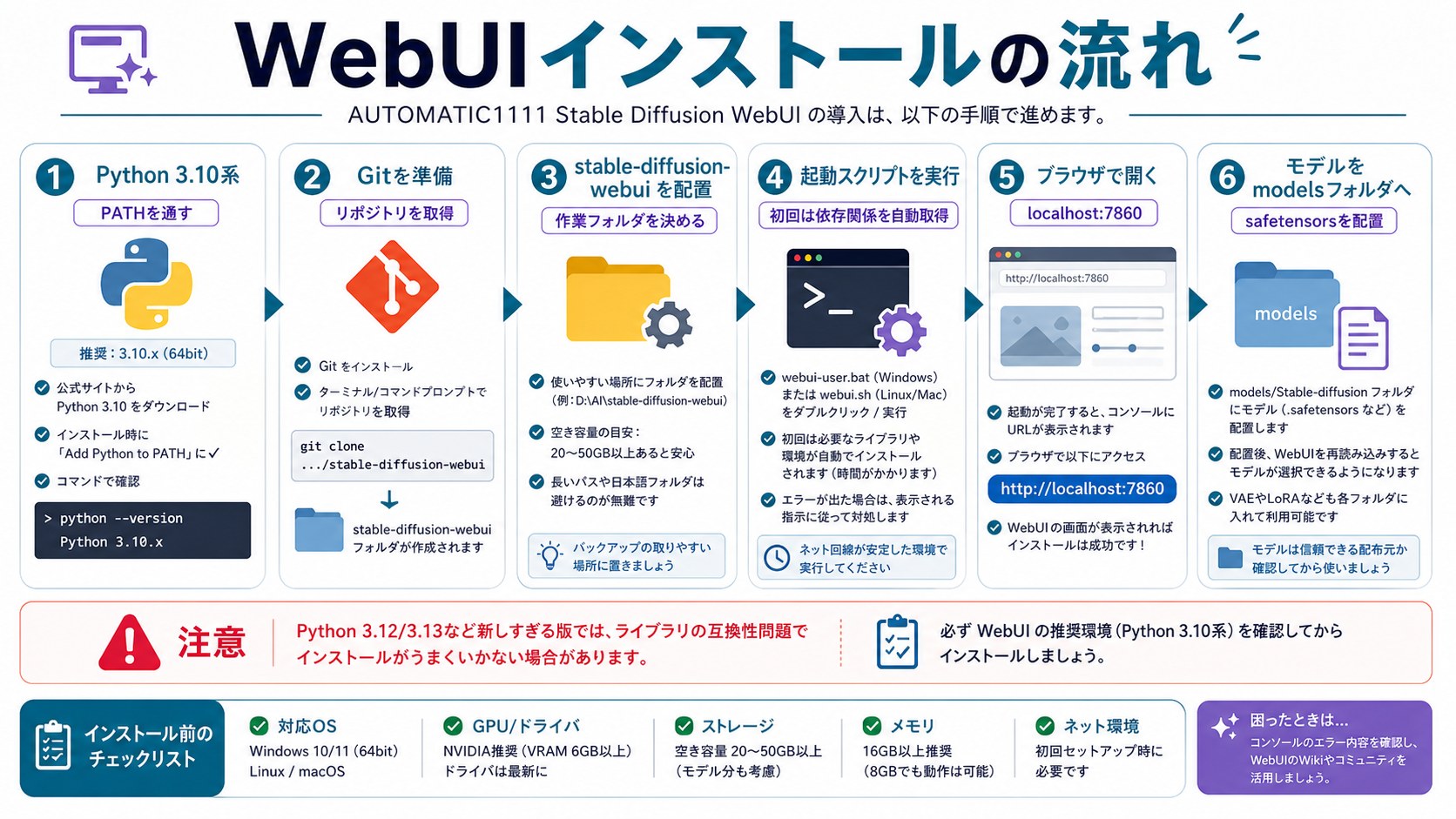
Windows版のインストール手順
事前準備:Pythonのインストール
https://www.python.org/downloads/にアクセスし、Python 3.10系(公式手順では3.10.6が案内されています)をダウンロード(3.11以降や新しすぎる版は、依存ライブラリの互換性でつまずく場合があります)- インストーラーを起動し、「Add Python to PATH」のチェックを必ず入れる
- 「Install Now」をクリックしてインストール完了
- コマンドプロンプトを開いて
python --versionと入力し、バージョンが表示されれば成功
事前準備:Gitのインストール
https://git-scm.com/download/winにアクセスしてGitをダウンロード・インストール- インストールオプションはデフォルトのまま「Next」で進めてOK
AUTOMATIC1111のインストール
- インストール先にしたいフォルダを開く(例:
C:\AIフォルダを新規作成) - フォルダ内で右クリック →「Git Bash Here」を選択
- 以下のコマンドを実行してリポジトリをクローンする:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
- クローンが完了したら
stable-diffusion-webuiフォルダが作成される - フォルダ内の
webui-user.batをダブルクリックして起動 - 初回起動時は依存ライブラリの自動インストールが始まる(5〜15分程度)
- コマンドプロンプト内に
Running on local URL: http://127.0.0.1:7860が表示されたらブラウザでhttp://127.0.0.1:7860を開く
Mac版(Apple Silicon)のインストール手順
- Homebrewをインストール済みでない場合は以下のコマンドをターミナルで実行:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- Pythonと必要なライブラリをインストール:
brew install cmake protobuf rust python@3.10 git wget
- リポジトリをクローン:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git ~/stable-diffusion-webui
- クローンしたフォルダに移動して起動スクリプトを実行:
cd ~/stable-diffusion-webui && ./webui.sh
- 初回起動時にモデルのダウンロードおよびライブラリのインストールが自動で進む
http://127.0.0.1:7860をブラウザで開く
基本モデル(チェックポイント)のダウンロード
AUTOMATIC1111は起動時に基本モデルを自動でダウンロードしますが、追加のモデルを手動で入れることもできます。モデルファイル(拡張子:.safetensors または .ckpt)を以下のフォルダに配置します:
stable-diffusion-webui/models/Stable-diffusion/
基本的な画像生成方法(txt2img)
AUTOMATIC1111が起動したら、最も基本的な「txt2img(テキストから画像生成)」機能で画像を生成してみましょう。
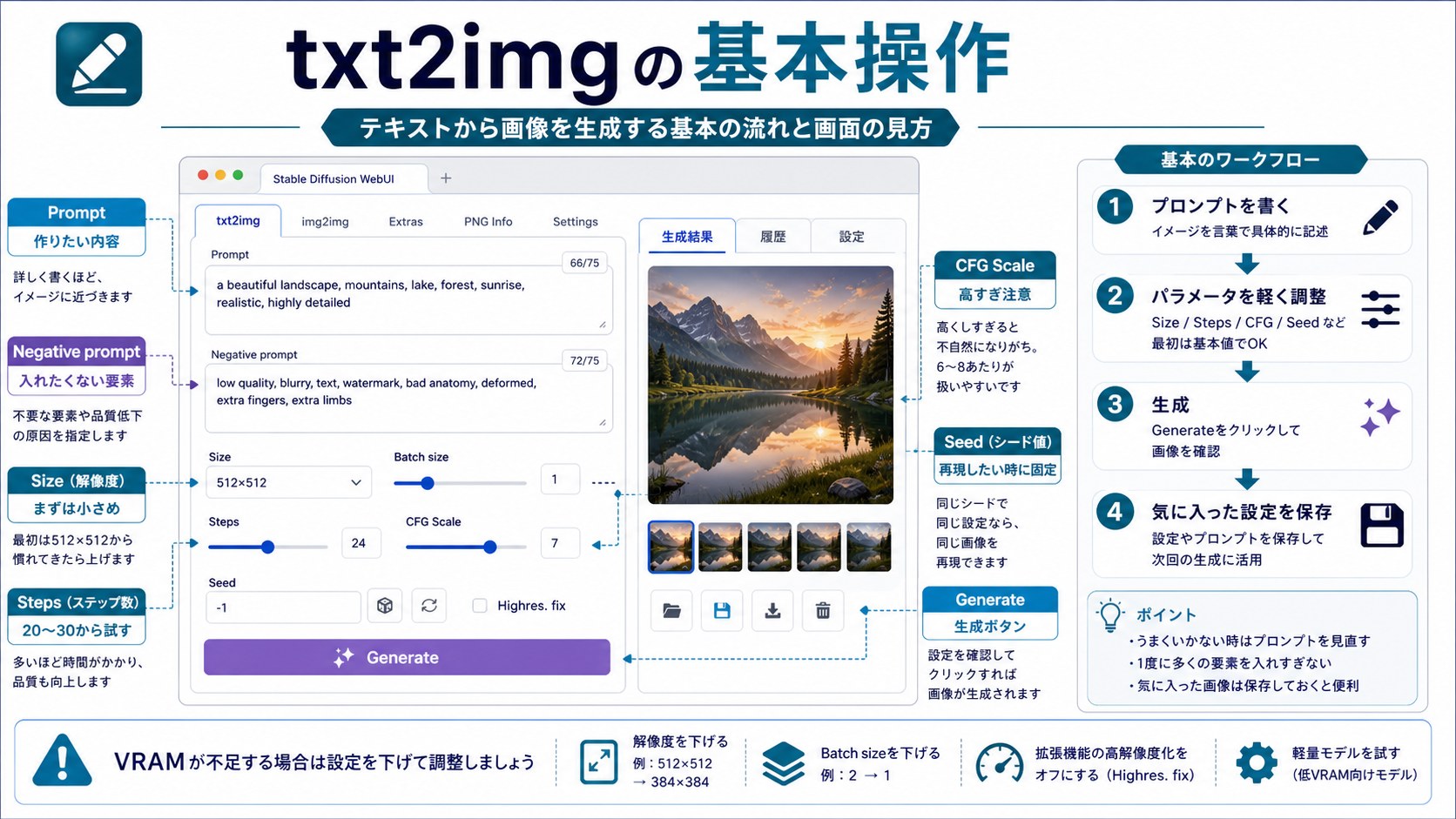
txt2imgの基本操作手順
- ブラウザで
http://127.0.0.1:7860を開く - 「txt2img」タブが選択されていることを確認
- Promptフィールド(上段の大きいテキストエリア)に生成したい画像の内容を英語で入力
- Negative promptフィールド(下段のテキストエリア)に含めたくない要素を入力
- 「Generate」ボタンをクリックして生成開始
- 数秒〜数十秒で画像が右側のプレビューエリアに表示される
主要なパラメーターの説明
| パラメーター | 説明 | 推奨値 |
|---|---|---|
| Sampling method | 画像生成アルゴリズム。品質と速度のバランスに影響 | DPM++ 2M Karras または Euler a |
| Sampling steps | 生成のステップ数。多いほど高品質だが時間がかかる | 20〜30 |
| Width / Height | 生成画像の縦横サイズ(ピクセル) | 512×512 または 768×512など |
| CFG Scale | プロンプトへの忠実度。高いとプロンプト通り、低いと自由な解釈 | 7〜12 |
| Seed | 乱数シード。同じシードで再現性のある生成が可能 | -1(ランダム)または固定値 |
| Batch size | 1回に生成する枚数 | 1〜4(VRAMに応じて調整) |
プロンプトとネガティブプロンプトの書き方
Stable Diffusionの画像品質を左右する最も重要な要素がプロンプトとネガティブプロンプトの書き方です。
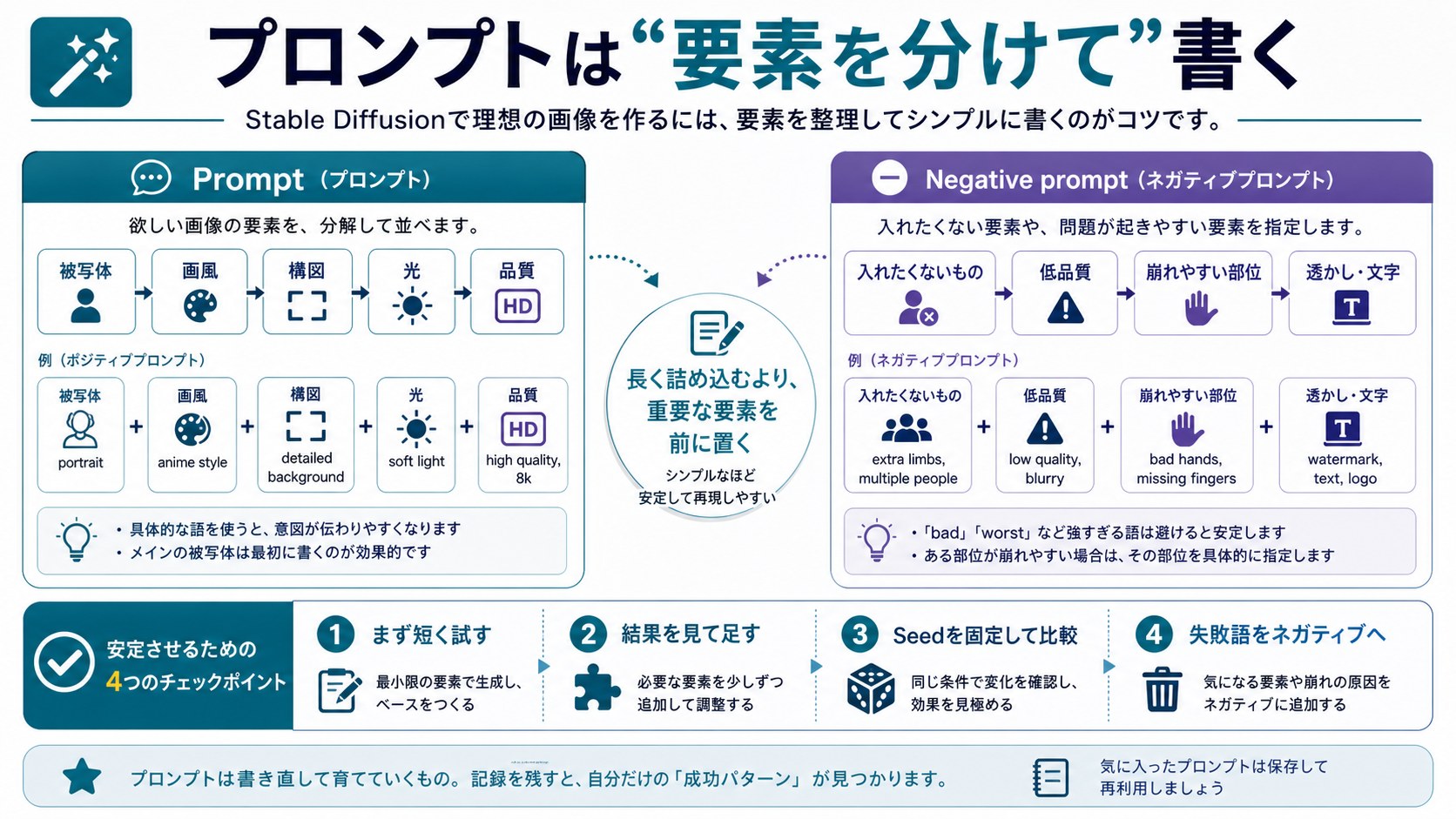
プロンプト(生成したいもの)の書き方
Stable Diffusionのプロンプトはカンマ区切りで要素を並べるのが基本スタイルです。前に書いた要素ほど強く反映される傾向があります。
推奨プロンプト例(人物・写真風):
masterpiece, best quality, 1girl, beautiful face, long brown hair, blue eyes, white dress, outdoors, sunlight, bokeh background, professional photography, 8k
推奨プロンプト例(風景・アニメ風):
masterpiece, best quality, anime style, beautiful landscape, cherry blossom, lake reflection, golden hour, detailed sky, studio ghibli, vibrant colors
ネガティブプロンプト(含めたくないもの)の書き方
ネガティブプロンプトは、画像に含まれてほしくない要素を指定します。これを適切に設定することで画質が劇的に向上します。
汎用ネガティブプロンプト(コピペ推奨):
worst quality, low quality, normal quality, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, jpeg artifacts, signature, watermark, username, blurry, artist name, text, error, missing limb, extra limb
重み付けの活用
キーワードを括弧で囲むことで重みを調整できます。
- (keyword):重みを1.1倍に増加
- ((keyword)):重みを1.21倍に増加
- (keyword:1.5):重みを1.5倍に増加(数値で直接指定)
- [keyword]:重みを0.9倍に減少
モデル(チェックポイント)の追加方法
Stable Diffusionの大きな魅力の一つが、コミュニティ製の多様なモデルを自由に追加できることです。アニメ特化モデル・リアル写真特化モデルなど、目的に合わせて使い分けられます。
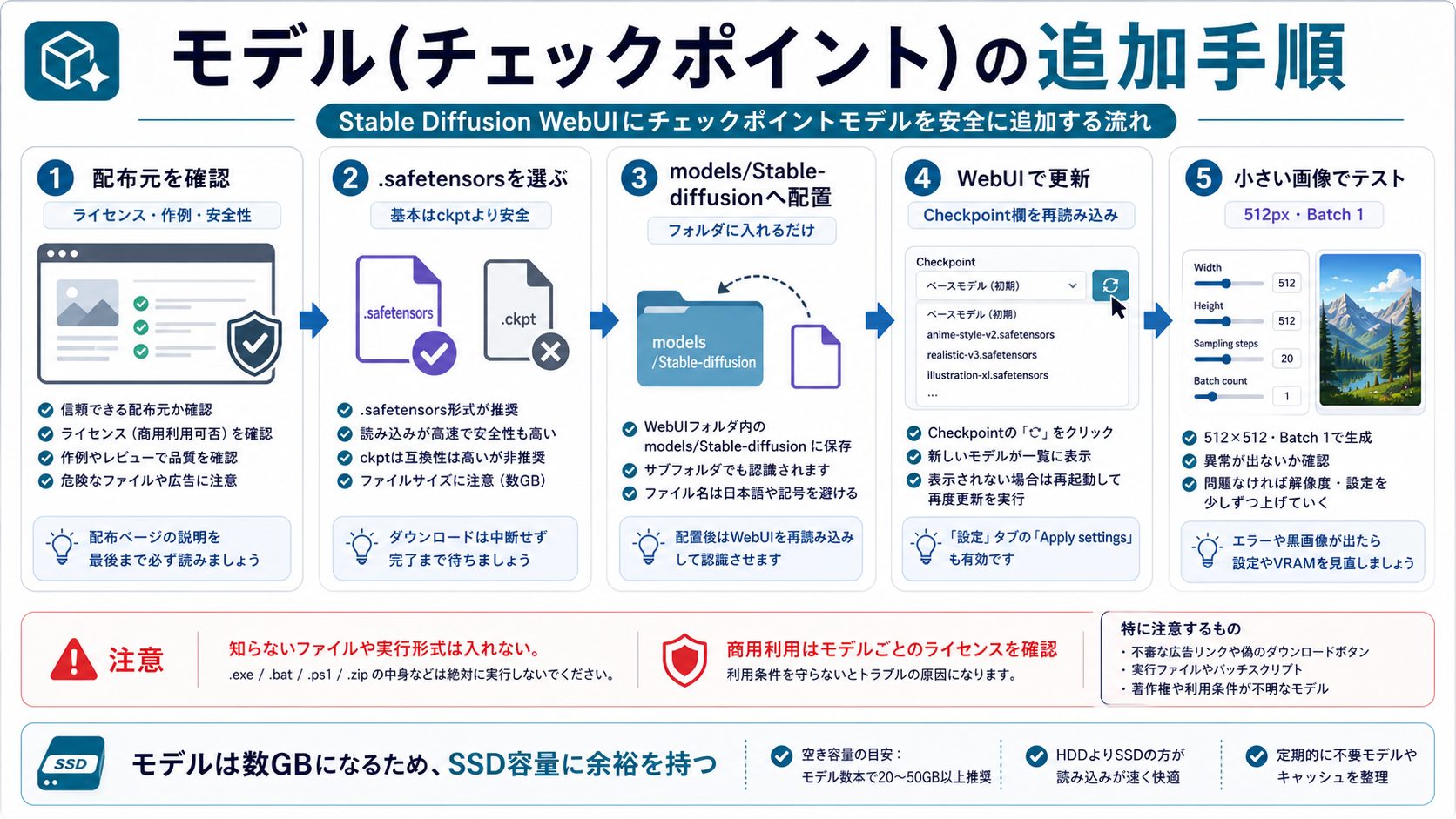
モデルのダウンロード先
- Civitai(シビタイ):最大のコミュニティモデル配布サイト(
https://civitai.com/) - Hugging Face:AIモデルの大手ホスティングサービス(
https://huggingface.co/)
モデルのインストール手順
- CivitaiまたはHugging Faceで目的のモデルを探す(例:「RealisticVision」「AnyLora Anime」など)
- モデルファイル(.safetensors または .ckpt、サイズは2〜7GB程度)をダウンロード
- ダウンロードしたファイルを以下のフォルダに移動:
stable-diffusion-webui/models/Stable-diffusion/
- AUTOMATIC1111のWebUIの「Checkpoint」ドロップダウンの更新ボタン(🔄)をクリック
- ドロップダウンから新しく追加したモデルを選択して使用開始
よくある質問(FAQ)
Q1. 「CUDA out of memory」というエラーが出て生成できません。
GPUのVRAMが不足しているエラーです。解決策として、(1) 生成画像の解像度(WidthおよびHeight)を小さくする(例:512×512)、(2) webui-user.batファイルを開いて COMMANDLINE_ARGS の行に --medvram または --lowvram を追記して起動する、(3) Batch sizeを1にする、などを試してください。
Q2. 生成した画像に手や指が変に描かれてしまいます。
Stable Diffusionは手の描写が苦手な場合があります。ネガティブプロンプトに bad hands, missing fingers, extra digit, fewer digits, deformed hands などを追加することで改善します。またHires.fixを有効にして高解像度で生成すると改善されることがあります。
Q3. 起動に毎回時間がかかります。速くする方法はありますか?
webui-user.batの COMMANDLINE_ARGS に --xformers を追記することで生成速度が向上し、メモリ使用量も削減されます(xformersライブラリの事前インストールが必要)。またSSD(特にNVMe SSD)にインストールすることで起動時間を短縮できます。
Q4. Macで動かそうとしていますが上手くいきません。
Apple SiliconのMacではMPS(Metal Performance Shaders)を使って動作します。起動時に --use-cpu all などのフラグが必要な場合があります。また、Python、PyTorch、依存ライブラリのバージョンの組み合わせに敏感なため、公式GitHubのMac向けインストール手順を必ず参照してください。2026年現在、M3 / M4 Macでは比較的スムーズに動作します。
Q5. 生成した画像の商用利用はできますか?
Stable Diffusion本体のライセンス(CreativeML Open RAIL-M License)では、生成した画像の商用利用は基本的に許可されています。ただし、使用するモデル(チェックポイント)によって個別のライセンスが異なります。Civitaiでダウンロードしたモデルは各モデルのライセンスを確認してください。
📚 あわせて読みたい
まとめ
Stable Diffusionは初期セットアップにある程度の技術知識が必要ですが、一度動かしてしまえば月額料金なしで無制限に高品質な画像を生成できるという圧倒的なメリットがあります。
重要なポイントをまとめると:
- 動かすにはNVIDIA GPU(4GB VRAM以上)が強く推奨される
- AUTOMATIC1111 WebUIを使えばブラウザ上で直感的に操作できる
- プロンプト(生成したいもの)とネガティブプロンプト(除外したいもの)の両方を設定することが品質向上の鍵
- Civitaiなどからモデルを追加することで画風の幅が大きく広がる
- パラメーター(Sampling steps・CFG Scale等)の調整で生成結果を細かくコントロールできる
最初はデフォルトの設定で試し、慣れてきたらモデル追加やパラメーター調整に挑戦してみてください。無限の可能性が広がるAI画像生成の世界をお楽しみください!
